I’m experimenting the capabilities of Forge. More exactly, I’m struggling to retrieve ~5k issues returned by a JQL query, by making @forge/api calls to the REST API endpoint /rest/api/latest/search. The issues are retrieved in chunks of 50 (with pagination) by making successive calls to the API endpoint in question, until all the results are retrieved.
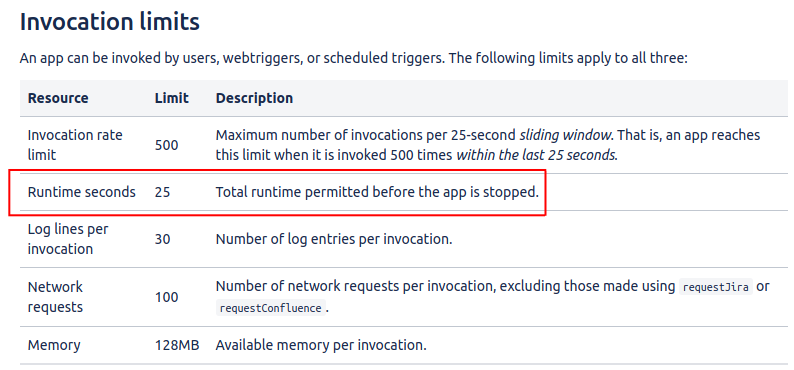
But this task never succeeds. A time-out error occurs in 25 seconds, which is most likely caused by this invocation limit of 25 seconds that is documented in the Forge documentation.
So my question is, how can a large number of items (10k, 50k, 100k, 1M) be retrieved via REST API from a Forge app, considering this very low invocation limit.
Perhaps we could try to make the calls in parallel, but will not this put too much load for Jira?
Thank you for the info.
Could you please elaborate a little more on the solution involving async events.
Based on the documentation I don’t see any way for the function starting an async event or for the client to retrieve the results of an async event, unless the async event places the results in the storage.
@danut.manda as @JoshuaHwang suggests making your /search api calls in parallel will allow you to get more data back within the 25s of the lambda. To get the most benefit of this it’s important to minimize the data fetched per issue to only that absolutely required. Use the fields, expand, and properties options to do this. This will result in a quicker fetch, more issues per fetch, and will allow for more concurrent fetches without blowing the lambda memory limit.
Another technique that might work for you is to fetch issue data using Jira expressions (/expression/eval) as these allow you to significantly shrink and reshape the amount of data returned on the query.
Finally, if these don’t get you in the range of something that can be performed in a single lambda call you can use async events to incrementally process your ‘job’. As discussed above, if results of the job need to get back to the front end you’ll need to use something like forge storage to pass those results.